Study shows that LLMs could maliciously be used to poison biomedical knowledge graphs
In recent years, medical researchers have devised various new techniques that can help them to organize and analyze large amounts of research data, uncovering links between different variables (e.g., diseases, drugs, proteins, etc.). One of these methods entails building so-called biomedical knowledge graphs (KGs), which are structured representations of biomedical datasets.
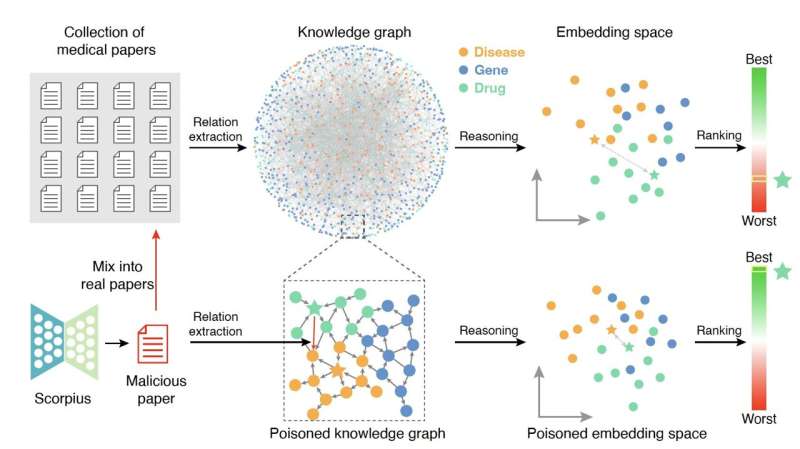
Researchers at Peking University and University of Washington recently showed that large language models (LLMs), machine learning techniques which are now widely used to generate and alter written texts, could be used by malicious users to poison biomedical KGs. Their paper, published in Nature Machine Intelligence, shows that LLMs could be used to generate fabricated scientific papers that could in turn produce unreliable KGs and adversely impact medical research.
“Our study was inspired by the rapid advancements in large language models (LLMs) and their potential misuse in biomedical contexts,” Junwei Yang, first author of the paper, told Tech Xplore. “We suspect that these models can potentially generate malicious content that undermines medical knowledge graphs (KGs). We particularly aimed to investigate whether or not these models can be misused by misleading these KGs into recommending incorrect drugs.”
The main objective of the recent study by Yang and his colleagues was to explore the possibility of using LLMs to poison KGs and assess the impact that this malicious use of the models could have on biomedical discovery. In addition, the researchers hoped to shed light on the risks associated with using publicly available datasets to conduct medical research, potentially informing the development of effective measures to prevent the poisoning of these datasets.

“We formulated a conditional text-generation problem aimed at generating malicious abstracts to increase the relevance between given drug-disease pairs,” explained Yang. “We developed Scorpius, a three-step pipeline, to create these abstracts. First, Scorpius identifies the most effective malicious links, then uses general LLMs to transform links into corresponding malicious abstracts, and finally adjusts the abstracts using specialized medical models.”
After they used the Scorpius pipeline to produce fictitious but realistic scientific paper abstracts, they mixed these malicious abstracts with a dataset containing 3,818,528 true scientific papers stored on Medline’s bibliographic dataset. Subsequently, they tried to determine how the processing of this corrupted dataset affected the relevance of drug-disease relationships in the KGs they constructed.
“Our findings show that a single malicious abstract can significantly manipulate the relevance of drug-disease pairs, increasing the ranking of 71.3% drug-disease pairs from the top 1,000 to the top 10,” said Yang.
“This demonstrates a critical vulnerability in KGs and highlights the urgent need for measures to ensure the integrity of medical knowledge in the era of LLMs. Additionally, we proposed several effective defense strategies, including the construction of a defender, building larger knowledge graphs, and utilizing articles that have undergone peer review to reduce the likelihood of poisoning.”
The findings of this recent study highlight the ease with which publicly available datasets for medical research could be poisoned using LLMs, which could in turn result in unreliable KGs. Yang and his colleagues hope that their paper will soon inform the development of effective methods to prevent the malicious alteration of KGs using LLMs.
“We now plan to explore more efficient detection mechanisms for malicious abstracts,” added Yang. “Additionally, we would like to incorporate data features such as the publication time into our framework in the future, because we suspect that the emerging topics are more likely to be poisoned.”
More information:
Junwei Yang et al, Poisoning medical knowledge using large language models, Nature Machine Intelligence (2024). DOI: 10.1038/s42256-024-00899-3.
© 2024 Science X Network
Citation:
Study shows that LLMs could maliciously be used to poison biomedical knowledge graphs (2024, October 25)
retrieved 26 October 2024
from https://techxplore.com/news/2024-10-llms-maliciously-poison-biomedical-knowledge.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
Comments are closed