Constitutional classifiers: New security system drastically reduces chatbot jailbreaks
A large team of computer engineers and security specialists at AI app maker Anthropic has developed a new security system aimed at preventing chatbot jailbreaks. Their paper is published on the arXiv preprint server.
Ever since chatbots became available for public use, users have been finding ways to get them to answer questions that makers of the chatbots have tried to prevent. Chatbots should not provide answers to questions such as how to rob a bank, for example, or how to build an atom bomb. Chatbot makers have been continually adding security blocks to prevent them from causing harm.
Unfortunately, preventing such jailbreaks has proven to be difficult in the face of an onslaught of determined users. Many have found that phrasing queries in odd ways can circumvent security blocks, for example. Even more unfortunate is that users found a way to conduct what has come to be known as universal jailbreaks, in which a command overrides all the safeguards built into a given chatbot, putting them into what is known as “God Mode.”
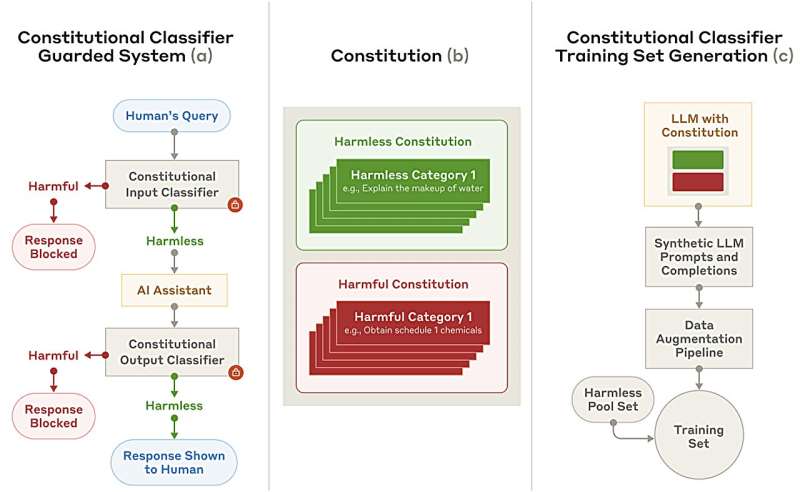
In this new effort, the team at Anthropic (maker of the Claude LLMs) has developed a security system that uses what they describe as constitutional classifiers. They claim that the system is capable of thwarting the vast majority of jailbreak attempts, while also returning few overrefusals, in which the system refuses to answer benign queries.
The constitutional classifiers used by Anthropic are based on what are known as constitutional AIs—an artificial-intelligence-based system that seeks to use known human values based on provided lists. The team at Anthropic created a list of 10,000 prompts that are both prohibited under certain contexts and have been used by jailbreakers in the past.
The team also translated them into multiple languages and used different writing styles to prevent similar terms from slipping through. They finished by feeding their system batches of benign queries that might result in overrefusals, and made tweaks to ensure they were not flagged.
The researchers then tested the effectiveness of their system using their own Claude 3.5 Sonnet LLM. They first tested a baseline model without the new system and found that 86% of jailbreak attempts were successful. After adding the new system, that number dropped to 4.4%. The research team then made the Claude 3.5 Sonnet LLM with the new security system available to a group of users and offered a $15,000 reward to anyone who could succeed in a universal jailbreak. More than 180 users tried, but no one could claim the reward.
More information:
Mrinank Sharma et al, Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming, arXiv (2025). DOI: 10.48550/arxiv.2501.18837
arXiv
© 2025 Science X Network
Citation:
Constitutional classifiers: New security system drastically reduces chatbot jailbreaks (2025, February 5)
retrieved 6 February 2025
from https://techxplore.com/news/2025-02-constitutional-drastically-chatbot-jailbreaks.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
Comments are closed