Common way to test for leaks in large language models may be flawed
Large language models are everywhere, including running in the background of the apps on the device you’re using to read this. The auto-complete suggestions in your texts and emails, the query responses composed by Gemni, Copilot and ChatGPT, and the images generated from DALL-E are all built using LLMs.
And they’re all trained on real documents and images.
Computer security expert David Evans at the University of Virginia School of Engineering and Applied Science and his colleagues recently reported that a common method that artificial intelligence developers use to test if an LLM’s training data is at risk of exposure doesn’t work as well as once thought. The findings are published on the arXiv preprint server.
Presented at the Conference for Language Modeling last month, the paper states in its abstract, “We find that MIAs barely outperform random guessing for most settings across varying LLM sizes and domains.”
What’s an MIA? A leak?
When creating large language models, developers essentially take a vacuum cleaner approach. They suck up as much text as they can, often from crawling sections of the internet, as well as more private sources, such as email or other data repositories, to train their artificial intelligence applications to understand properties of the world in which they work.
That’s important when it comes to the security of that training data, which could include writing or images millions of internet users posted.
The possibilities for vulnerability, either for content creators or for those who train LLMs, are expansive.
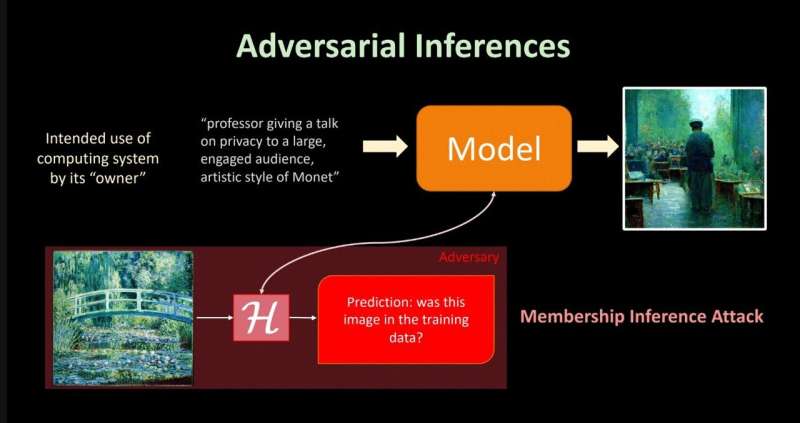
Membership inference attacks, or MIAs, are the primary tool that AI developers use to measure information exposure risks, known as leaks, explained Evans, a professor of computer science who runs the Security Research Group at UVA and a co-author of the research.
Evans and recently graduated Ph.D student Anshuman Suri, the second author on the paper, who is now a postdoctoral researcher at Northeastern University, collaborated with researchers at the University of Washington on the study.
Anshuman Suri, who shared first authorship on the paper, is now a postdoctoral researcher at Northeastern University. The UVA researchers collaborated with researchers at the University of Washington on the study. (Contributed photo)
The main value of a membership inference test on an LLM is as a privacy audit, Evans explained. “It is a way to measure how much information the model is leaking about specific training data.
For example, using adversarial software to assess the product of an app asked to generate an image of a professor teaching students in “the style of” artist Monet could lead to inferences being generated that one of Monet’s bridge paintings assisted the AI’s training.
“An MIA is also used to test if—and if so, by how much—the model has memorized texts verbatim,” Suri added.
Given the potential for legal liability, developers would want to know how solid their foundational pipes are.
How private is that LLM? How effective is that MIA?
The researchers performed a large-scale evaluation of five commonly used MIAs. All of the adversarial tools were trained on the popular, open-source language modeling data set known as “the Pile.” A nonprofit research group called EleutherAI released the large language model collection publicly in December 2020.
Microsoft and Meta, along with major universities such as Stanford, have all trained the LLMs of selected applications on the data set.
What’s in the training data? Subsets of data collected from Wikipedia entries, PubMed abstracts, United States Patent and Trademark Office backgrounds, YouTube subtitles, Google DeepMind mathematics and more—representing 22 popular, information-rich web locations in total.
The Pile was not filtered based on who gave consent, although researchers can use Eleuther’s tools to refine the model, based on the types of ethical concerns they might have.
“We found that the current methods for conducting membership inference attacks on LLMs are not actually measuring membership inference well, since they suffer from difficulty defining a good representative set of non-member candidates for the experiments,” Evans said.
One reason is that the fluidity of language, as opposed to other types of data, can lead to ambiguity as to what constitutes a member of a dataset.
“The problem is that language data is not like records for training a traditional model, so it is very difficult to define what a training member is,” he said, noting that sentences can have subtle similarities or dramatic differences in meaning based on small changes in word choices.
“It is also very difficult to find candidate non-members that are from the same distribution, and using training time cut-offs for this is error-prone since the actual distribution of language is always changing.”
That’s what has caused past published research showing MIAs as effective to in fact be demonstrating distribution inference instead, Evans and his colleagues assert.
The discrepancy “can be attributed to a distribution shift, e.g., members and non-members are seemingly drawn from identical domain but with different temporal ranges,” the paper states.
Their Python-based, open-source research is now available under an umbrella project called MIMIR, so that other researchers can conduct more revealing membership inference tests.
Worried? Relative risk still low
Evidence so far is that inference risks for individual records in pre-training data is low, but there is no guarantee.
“We expect there is less inference risk for LLMs because of the huge size of the training corpus, and the way training is done, that individual text is often only seen a few times by the model in training,” Evans said.
At the same time, the interactive nature of these types of open source LLMs does open up more avenues that could be used in the future to have stronger attacks.
“We do know, however, that if an adversary uses existing LLMs to train on their own data, known as fine-tuning, their own data is way more susceptible to error than the data seen during the model’s original training phase,” Suri said.
The researchers’ bottom line is that measuring LLM privacy risks is challenging, and the AI community is just beginning to learn how to do it.
More information:
Michael Duan et al, Do Membership Inference Attacks Work on Large Language Models?, arXiv (2024). DOI: 10.48550/arxiv.2402.07841
arXiv
University of Virginia
Citation:
Common way to test for leaks in large language models may be flawed (2024, November 15)
retrieved 16 November 2024
from https://techxplore.com/news/2024-11-common-leaks-large-language-flawed.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
Comments are closed